New API 是新一代 AI 网关与资产管理系统,作为 AI 基座平台,提供统一基础设施接入全球 30+ 主流 AI 服务(OpenAI、Claude、Gemini、DeepSeek 等)。平台核心特性包括统一 OpenAI 兼容接口、智能路由负载均衡、精细计费与权限管控、实时数据看板。平台支持多格式转换、推理力度控制、缓存计费等高级功能。采用 AGPLv3 开源协议,支持 Docker 一键部署,适配个人开发者到企业级多租户场景。
New API的主要功能
统一接口管理:提供兼容 OpenAI 格式的单一 API 端点,无缝接入全球 30+ 主流 AI 服务提供商。
智能路由调度:支持多渠道负载均衡、故障自动切换和加权随机分发,确保服务高可用性。
精细计费系统:支持实现按次数或按量计费、预付费充值、多倍率配置及缓存计费支持。
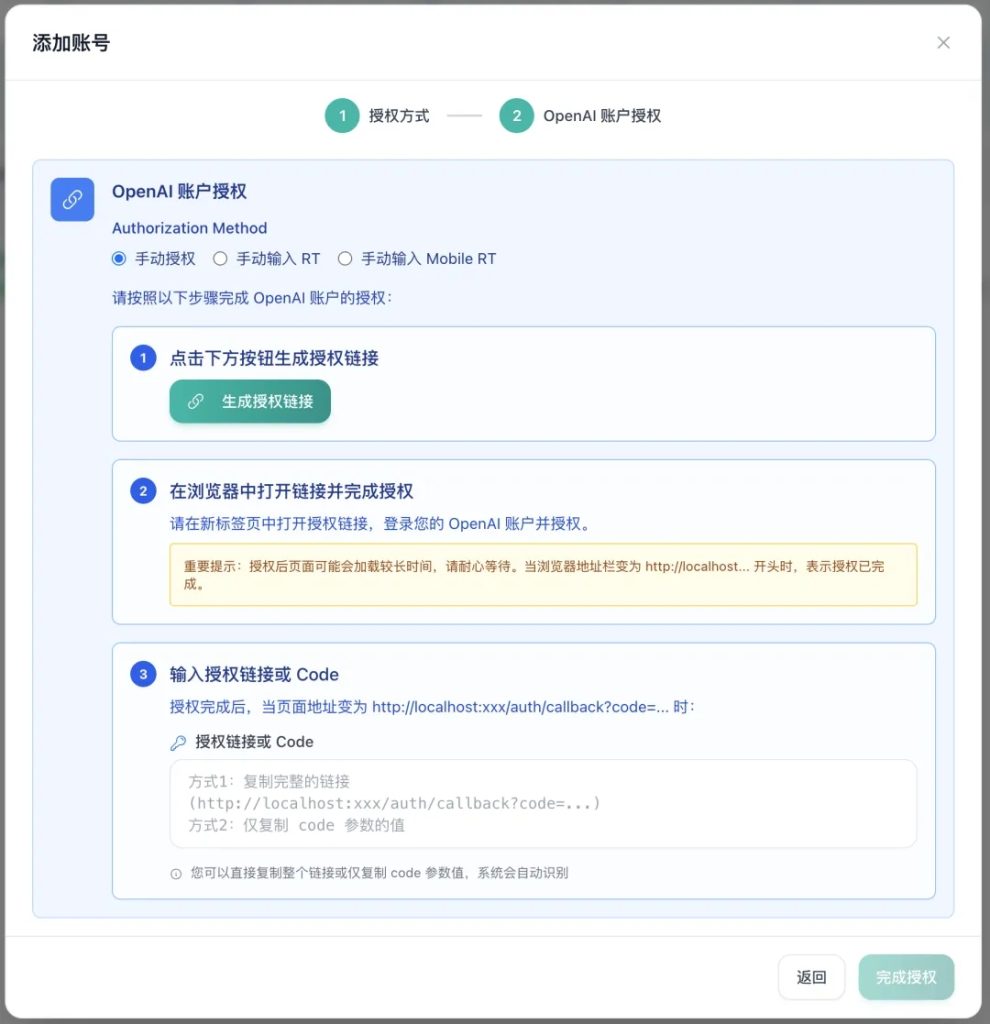
安全权限管控:提供令牌分组管理、模型访问限制、API 调用审计及多平台授权登录。
格式转换能力:支持 OpenAI、Claude Messages、Google Gemini 等多种 API 格式之间的相互转换。
推理力度控制:支持通过模型名称后缀灵活设置高、中、低不同级别的推理思考强度。
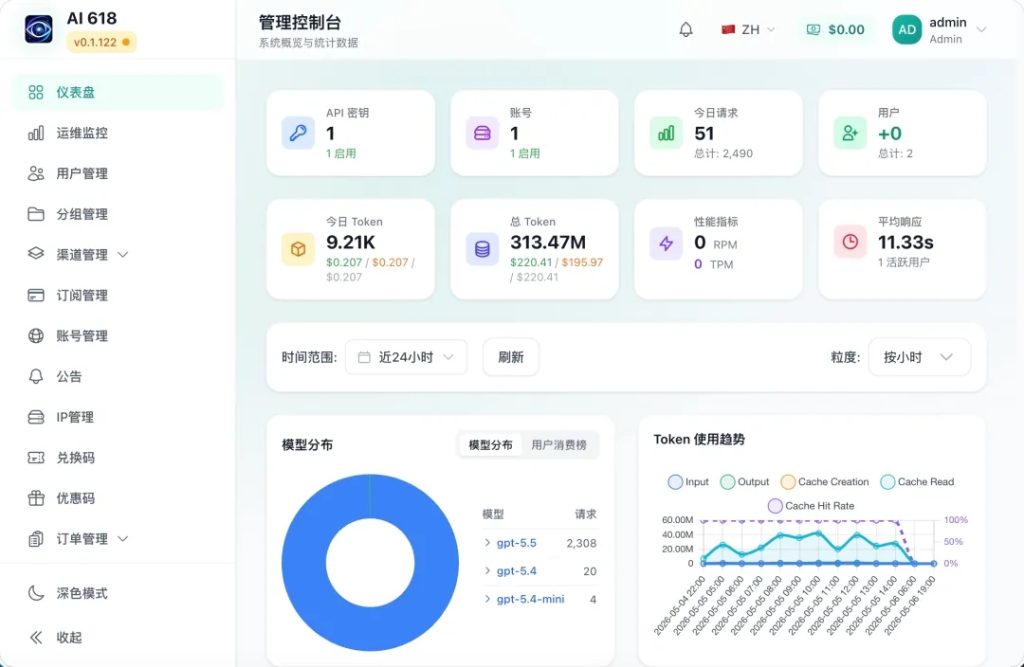
实时数据看板:提供可视化控制台、用量统计分析和成本监控的数据洞察功能。
New API的关键信息和使用要求
项目定位:新一代 AI 网关与资产管理系统,AI 基座平台
开源协议:GNU AGPLv3(可免费使用,SaaS 部署需开源)
兼容基础:基于 One API 开发,完全兼容原数据库
支持语言:简中、繁中、英文、法文、日文
部署方式:Docker / Docker Compose / 宝塔面板
数据库:SQLite(默认)/ MySQL ≥ 5.7.8 / PostgreSQL ≥ 9.6
Docker 镜像:calciumion/new-api:latest
New API的核心优势
统一接入:通过一个兼容 OpenAI 格式的 API 端点,可无缝接入全球 30+ 主流 AI 服务提供商,彻底告别多平台对接的繁琐工作。
智能路由:平台内置多渠道负载均衡、故障自动切换和加权随机分发机制,确保 AI 服务的高可用性和请求稳定性。
成本优化:支持缓存计费、按量或按次计费以及多倍率灵活配置,帮助用户实现精细化的成本控制和费用管理。
格式互通:提供 OpenAI、Claude Messages、Google Gemini 等多种 API 格式之间的自由转换能力,显著降低不同模型的接入门槛。
开箱即用:支持 Docker 一键部署,完全兼容 One API 数据库,提供宝塔面板可视化安装,极大简化部署流程。
• Claude Code:目前的”天花板”,也是最傲娇的。 Anthropic 对国内用户的敌意真的是写在脸上的。最近 Claude Code 甚至要搞 KYC 认证,只认护照、驾照原件,复印件和照片统统拒收。圈里有个梗:说是不知道当年百度对 Anthropic 的 CEO 做了什么,让人家记恨至今。 梗归梗,但它成本高、风控严是事实。即便如此,大家还是趋之若鹜,这真不是崇洋媚外,只有真正干活的人才知道,顶级模型那种”指哪打哪”的逻辑感,国内模型暂时还听不懂这种”人话”。